企业邮箱
|
中文
|
English
联系电话:
029-8958 8822
资料请求/留言
首页
鼎搏体育安全·「中国」有限责任公司
鼎搏体育安全·「中国」有限责任公司
资讯中心
资料中心
联系我们
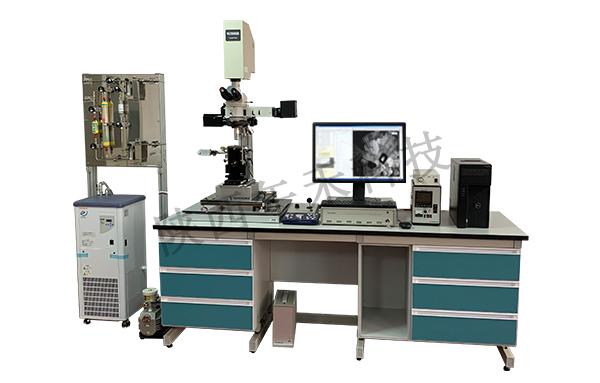
超高温激光共聚焦显微镜
高温拉压激光共聚焦显微镜
全自动逐层切片成像系统
多功能真实色共聚焦显微镜
技术资讯
行业新闻
公司新闻
08
24-03
实验邀请|高温原位观察+真实色共聚焦扫...
27
24-02
新品来袭|高温熔融拉伸系统,助力焊接领...
15
23-11
关于“局部加热”,我们有这些解决方案...
08
23-10
预裂纹和组织对高强度钢脆性破坏的影响...
24
23-08
高温合金|助力科研,我们在行动!
21
23-07
新品来袭|高温力学试验机,对新材料的高...
15
24-03
安装篇|华北理工大学超高温激光共聚焦显...
05
24-01
专刊邀稿|《钢铁研究学报》英文版邀稿啦...
14
23-12
午禾科技参与起草的《钢中晶粒尺寸测定...
24
23-04
安装篇|【午禾科技】引领材料科研领域走...
05
22-07
来源:【材料学网】中科院金属所《Act...
27
22-05
来源:【材料科学与工程】顶刊《Acta M...
29
24-01
2024年春节放假通知
29
23-12
2024年元旦放假通知
27
23-09
2023年中秋节&国庆节放假通知
20
23-06
2023年端午节放假通知
31
23-05
寻找发光的你|午禾科技“校园合伙人”招...
21
23-04
2023年五一劳动节放假通知
友情链接:
村上色彩研究所
Kunoh
Lasertec
Nanmac
Optika
Sigmakoki
Yonekura
乐竞体育·(中国)官方网站
|
线上买球
|
bob官网官方【中国】集团有限公司
|
新利·体育(中国)官方网站
|
星空平台
|
九州网站(中国) 官网登录
|
V8游戏V8游戏中心
|
开云网页版
|
九州平台
|